搜索到
257
篇与
的结果
-
 【PHP】ThinkPHP6 公共 上传到本地的方法 附带使用方法 <?php namespace app\common\lib\files; use think\Exception; use think\exception\ValidateException; class upload { private $domain; protected $name; protected $type; protected $module; protected $image; public function __construct($name = '',$type = 'image',$image = []) { $this->name = $name; $this->type = $this->checkUpload($type); $this->module = request()->app_name(); $this->image = $image; $this->domain = Request()->domain(); } protected $config = [ 'image' => [ 'validate' => [ 'size' => 10*1024*1024, 'ext' => 'jpg,png,gif,jpeg', ], 'path' => '/images', ], 'audio' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp3,wav,cd,ogg,wma,asf,rm,real,ape,midi', ], 'path' => '/audios', ], 'video' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp4,avi,rmvb,rm,mpg,mpeg,wmv,mkv,flv', ], 'path' => '/videos', ], 'file' => [ 'validate' => [ 'size' => 5*1024*1024, 'ext' => 'doc,docx,xls,xlsx,pdf,ppt,txt,rar,zip,pem,p12', ], 'path' => '/files', ], ]; private function checkUpload($type){ try{ if(empty($_FILES) || empty($_FILES[$this->name])) throw new Exception("未上传文件!"); if(!in_array($type,array_keys($this->config))) throw new Exception("文件类型不存在!"); return $type; }catch (Exception $e){ return \app\common\controller\Base::show(100,$e->getMessage()); } } public function upfile($infoSwitch = false){ $file = request()->file($this->name); try{ if($file == null) throw new ValidateException("the file cannot be empty"); validate(['file' => self::validateFile()])->check(['file' => $file]); $savename = \think\facade\Filesystem::disk('public')->putFile( $this->module.$this->config[$this->type]['path'], $file); if($infoSwitch){ return self::getFileInfo($file,$savename); } return $savename; }catch (\think\exception\ValidateException $e){ return \app\common\controller\Base::show(100,self::languageChange($e->getMessage())); } } private function validateFile(){ if(empty($this->image)){ $validataType = [ 'fileSize' => $this->config[$this->type]['validate']['size'], 'fileExt' => $this->config[$this->type]['validate']['ext'], ]; }else{ if(is_array($this->image)) throw new ValidateException(""); $validataType = [ 'fileSize' => $this->config[$this->type]['validate']['size'], 'fileExt' => $this->config[$this->type]['validate']['ext'], 'image' => $this->image //示例值 [200,200] ]; } return $validataType; } private function languageChange($msg){ $data = [ 'the file cannot be empty' => '文件不能为空!', 'unknown upload error' => '未知上传错误!', 'file write error' => '文件写入失败!', 'upload temp dir not found' => '找不到临时文件夹!', 'no file to uploaded' => '没有文件被上传!', 'only the portion of file is uploaded' => '文件只有部分被上传!', 'upload File size exceeds the maximum value' => '上传文件大小超过了最大值!', 'upload write error' => '文件上传保存错误!', ]; return $data[$msg] ?? $msg; } private function getFileInfo($file,$savename){ $info = [ 'path' => config('filesystem.disks.public.url').'/'.str_replace('\\','/',$savename), 'url' => $this->domain.config('filesystem.disks.public.url').'/'.str_replace('\\','/',$savename), 'size' => $file->getSize(), 'name' => $file->getOriginalName(), 'mime' => $file->getMime(), 'ext' => $file->extension() ]; return $info; } } > 使用方法 : > > $instanceUpload = new upload($fileName,$fileType); > $info = $instanceUpload->upfile(true);
【PHP】ThinkPHP6 公共 上传到本地的方法 附带使用方法 <?php namespace app\common\lib\files; use think\Exception; use think\exception\ValidateException; class upload { private $domain; protected $name; protected $type; protected $module; protected $image; public function __construct($name = '',$type = 'image',$image = []) { $this->name = $name; $this->type = $this->checkUpload($type); $this->module = request()->app_name(); $this->image = $image; $this->domain = Request()->domain(); } protected $config = [ 'image' => [ 'validate' => [ 'size' => 10*1024*1024, 'ext' => 'jpg,png,gif,jpeg', ], 'path' => '/images', ], 'audio' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp3,wav,cd,ogg,wma,asf,rm,real,ape,midi', ], 'path' => '/audios', ], 'video' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp4,avi,rmvb,rm,mpg,mpeg,wmv,mkv,flv', ], 'path' => '/videos', ], 'file' => [ 'validate' => [ 'size' => 5*1024*1024, 'ext' => 'doc,docx,xls,xlsx,pdf,ppt,txt,rar,zip,pem,p12', ], 'path' => '/files', ], ]; private function checkUpload($type){ try{ if(empty($_FILES) || empty($_FILES[$this->name])) throw new Exception("未上传文件!"); if(!in_array($type,array_keys($this->config))) throw new Exception("文件类型不存在!"); return $type; }catch (Exception $e){ return \app\common\controller\Base::show(100,$e->getMessage()); } } public function upfile($infoSwitch = false){ $file = request()->file($this->name); try{ if($file == null) throw new ValidateException("the file cannot be empty"); validate(['file' => self::validateFile()])->check(['file' => $file]); $savename = \think\facade\Filesystem::disk('public')->putFile( $this->module.$this->config[$this->type]['path'], $file); if($infoSwitch){ return self::getFileInfo($file,$savename); } return $savename; }catch (\think\exception\ValidateException $e){ return \app\common\controller\Base::show(100,self::languageChange($e->getMessage())); } } private function validateFile(){ if(empty($this->image)){ $validataType = [ 'fileSize' => $this->config[$this->type]['validate']['size'], 'fileExt' => $this->config[$this->type]['validate']['ext'], ]; }else{ if(is_array($this->image)) throw new ValidateException(""); $validataType = [ 'fileSize' => $this->config[$this->type]['validate']['size'], 'fileExt' => $this->config[$this->type]['validate']['ext'], 'image' => $this->image //示例值 [200,200] ]; } return $validataType; } private function languageChange($msg){ $data = [ 'the file cannot be empty' => '文件不能为空!', 'unknown upload error' => '未知上传错误!', 'file write error' => '文件写入失败!', 'upload temp dir not found' => '找不到临时文件夹!', 'no file to uploaded' => '没有文件被上传!', 'only the portion of file is uploaded' => '文件只有部分被上传!', 'upload File size exceeds the maximum value' => '上传文件大小超过了最大值!', 'upload write error' => '文件上传保存错误!', ]; return $data[$msg] ?? $msg; } private function getFileInfo($file,$savename){ $info = [ 'path' => config('filesystem.disks.public.url').'/'.str_replace('\\','/',$savename), 'url' => $this->domain.config('filesystem.disks.public.url').'/'.str_replace('\\','/',$savename), 'size' => $file->getSize(), 'name' => $file->getOriginalName(), 'mime' => $file->getMime(), 'ext' => $file->extension() ]; return $info; } } > 使用方法 : > > $instanceUpload = new upload($fileName,$fileType); > $info = $instanceUpload->upfile(true); -
【PHP】PHP快速读取大文件指定行的方法 1、面临问题分析读取普通小文件我们一般用fopen 或者 file_get_contents就很方便简单 ,前者可以循环读取,后者可以一次性读取,但都是将文件内容一次性加载来操作。如果加载的文件特别大时,如几百M、上G时,这时性能贫瘠就非常突出了,那么PHP里有没有对大文件的处理函数或者类呢? 答案是:有的。2、SplFileObject类高效解决大文件读取问题从 PHP 5.1.0 开始,SPL 库增加了 SplFileObject 与 SplFileInfo 两个标准的文件操作类。从字面意思理解看,可以看出 SplFileObject 要比 SplFileInfo 更为强大。不错,SplFileInfo 仅用于获取文件的一些属性信息,如文件大小、文件访问时间、文件修改时间、后缀名等值,而 SplFileObject 是继承 SplFileInfo 这些功能并新增很多文件处理类操作方法的一个文件操作类。 /** 返回文件从X行到Y行的内容(支持php5、php4) * @param string $filename 文件名 * @param int $startLine 开始的行数 * @param int $endLine 结束的行数 * @return string */ function getFileLines($filename, $startLine = 1, $endLine=50, $method='rb') { $content = array(); $count = $endLine - $startLine; // 判断php版本(因为要用到SplFileObject,PHP>=5.1.0) if(version_compare(PHP_VERSION, '5.1.0', '>=')){ $fp = new SplFileObject($filename, $method); $fp->seek($startLine-1);// 转到第N行, seek方法参数从0开始计数 for($i = 0; $i <= $count; ++$i) { $content[]=$fp->current();// current()获取当前行内容 $fp->next();// 下一行 } }else{//PHP<5.1 $fp = fopen($filename, $method); if(!$fp) return 'error:can not read file'; for ($i=1;$i<$startLine;++$i) {// 跳过前$startLine行 fgets($fp); } for($i;$i<=$endLine;++$i){ $content[]=fgets($fp);// 读取文件行内容 } fclose($fp); } return array_filter($content); // array_filter过滤:false,null,'' }Ps:(1)、上面都没加”读取到末尾的判断”:!$fp->eof() 或者 !feof($fp),结果实践加上这个判断影响效率,而且这里加上也完全没必要。(2)、从上面的函数和实践操作就可以看出来使用SplFileObject类比下面的fgets函数效率要高很多,特别是文件行数非常多、并且要取越后面的内容的时候。fgets要两个循环才可以。
-
【PHP】PHP读取文件指定行的内容 function getLine($file, $line, $length = 40960){ $returnTxt = null; // 初始化返回 $i = 1; // 行数 $handle = @fopen($file, "r"); if ($handle) { while (!feof($handle)) { $buffer = fgets($handle, $length); if($line == $i) $returnTxt = $buffer; $i++; } fclose($handle); } return $returnTxt; }
-
【PHP】ThinkPHP 5.1公共上传类 <?php namespace app\extra; /* * To change this license header, choose License Headers in Project Properties. * To change this template file, choose Tools | Templates * and open the template in the editor. */ //适配移动设备图片上传 use think\Exception; use think\facade\Request; class ExtraUpload{ /** * 默认上传配置 * @var array */ private $config = [ 'image' => [ 'validate' => [ 'size' => 10*1024*1024, 'ext' => 'jpg,png,gif,jpeg', ], 'rootPath' => './Uploads/images/', //保存根路径 ], 'audio' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp3,wav,cd,ogg,wma,asf,rm,real,ape,midi', ], 'rootPath' => './Uploads/audios/', //保存根路径 ], 'video' => [ 'validate' => [ 'size' => 100*1024*1024, 'ext' => 'mp4,avi,rmvb,rm,mpg,mpeg,wmv,mkv,flv', ], 'rootPath' => './Uploads/videos/', //保存根路径 ], 'file' => [ 'validate' => [ 'size' => 5*1024*1024, 'ext' => 'doc,docx,xls,xlsx,pdf,ppt,txt,rar', ], 'rootPath' => './Uploads/files/', //保存根路径 ], ]; private $domain; function __construct() { //获取当前域名 $this->domain = Request::instance()->domain(); } public function upload($fileName){ if(empty($_FILES) || empty($_FILES[$fileName])){ // return ''; returnResponse(100,'文件为空'); } try{ $file = request()->file($fileName); if (is_array($file)){ $path = []; foreach ($file as $item){ $path[] = $this->save($item); } } else { $path = $this->save($file); } return $path; } catch (\Exception $e){ $arr = [ 'status' => 0, 'message' => $e->getMessage(), ]; header('Content-Type: application/json; charset=UTF-8'); exit(json_encode($arr)); } } public function uploadDetail($fileName){ if(empty($_FILES) || empty($_FILES[$fileName])){ // return []; returnResponse(100,'文件为空'); } try{ $file = request()->file($fileName); if (is_array($file)){ $path = []; foreach ($file as $item){ $detail = $item->getInfo(); $returnData['name'] = $detail['name']; $returnData['type'] = $detail['type']; $returnData['size'] = $detail['size']; $returnData['filePath'] = $this->save($item); $returnData['fullPath'] = $this->domain.$returnData['filePath']; $path[] = $returnData; } } else { $detail = $file->getInfo(); $returnData['name'] = $detail['name']; $returnData['type'] = $detail['type']; $returnData['size'] = $detail['size']; $returnData['filePath'] = $this->save($file); $returnData['fullPath'] = $this->domain.$returnData['filePath']; $path = $returnData; } return $path; } catch (\Exception $e){ $arr = [ 'status' => 0, 'message' => $e->getMessage(), ]; header('Content-Type: application/json; charset=UTF-8'); exit(json_encode($arr)); } } private function getConfig($file){ $name = pathinfo($file['name']); $end = $name['extension']; foreach ($this->config as $key=>$item){ if ($item['validate']['ext'] && strpos($item['validate']['ext'], $end) !== false){ return $this->config[$key]; } } return null; } private function save(&$file){ $config = $this->getConfig($file->getInfo()); if (empty($config)){ throw new Exception('上传文件类型不被允许!'); } // 移动到框架应用根目录/uploads/ 目录下 if ($config['validate']) { $file->validate($config['validate']); $result = $file->move($config['rootPath']); } else { $result = $file->move($config['rootPath']); } if($result){ $path = $config['rootPath']; if (strstr($path,'.') !== false){ $path = str_replace('.', '', $path); } return $path.$result->getSaveName(); }else{ // 上传失败获取错误信息 throw new Exception($file->getError()); } } } 使用方法: $p = new \app\extra\ExtraUpload(); return $p->uploadDetail('file');
-
【PHP】opcache是用来干嘛的? opcache从字面意思,肯定是缓存这一块的。但是你是否知道它的工作原理是怎样的呢?这里一点一点让你了解!PHP项目中,尤其是在高并发大流量的场景中,如何提升PHP的响应时间,是一项十分重要的工作。而Opcache又是优化PHP性能不可缺失的组件,尤其是应用了PHP框架的项目中,作用更是明显。概述在理解 OPCache 功能之前,我们有必要先理解PHP-FPM + Nginx 的工作机制,以及PHP脚本解释执行的机制。1.1 PHP-FPM + Nginx 的工作机制请求从Web浏览器到Nginx,再到PHP处理完成,一共要经历如下五个步骤:第一步:启动服务启动PHP-FPM。PHP-FPM 支持两种通信模式:TCP socket和Unix socket;PHP-FPM 会启动两种类型的进程:Master 进程 和 Worker 进程,前者负责监控端口、分配任务、管理Worker进程;后者就是PHP的cgi程序,负责解释编译执行PHP脚本。启动Nginx。首先会载入 ngx_http_fastcgi_module 模块,初始化FastCGI执行环境,实现FastCGI协议请求代理这里要注意:fastcgi的worker进程(cgi进程),是由PHP-FPM来管理,不是Nginx。Nginx只是代理第二步:Request => NginxNginx 接收请求,并基于location配置,选择一个合适handler这里就是代理PHP的 handler第三步:Nginx => PHP-FPMNginx 把请求翻译成fastcgi请求通过TCP socket/Unix Socket 发送给PHP-FPM 的master进程第四步:PHP-FPM Master => WorkerPHP-FPM master 进程接收到请求分配Worker进程执行PHP脚本,如果没有空闲的Worker,返回502错误Worker(php-cgi)进程执行PHP脚本,如果超时,返回504错误处理结束,返回结果第五步:PHP-FPM Worker => Master => NginxPHP-FPM Worker 进程返回处理结果,并关闭连接,等待下一个请求PHP-FPM Master 进程通过Socket 返回处理结果Nginx Handler顺序将每一个响应buffer发送给第一个filter → 第二个 → 以此类推 → 最终响应发送给客户端1.2 PHP脚本解释执行的机制了解了PHP + Nginx 整体的处理流程后,我们接下来看一下PHP脚本具体执行流程,首先我们看一个实例: <?php if (!empty($_POST)) { echo "Response Body POST: ", json_encode($_POST), "\n"; } if (!empty($_GET)) { echo "Response Body GET: ", json_encode($_GET), "\n"; }我们分析一下执行过程:1.php初始化执行环节,启动Zend引擎,加载注册的扩展模块2.初始化后读取脚本文件,Zend引擎对脚本文件进行词法分析(lex),语法分析(bison),生成语法树3.Zend 引擎编译语法树,生成opcode,4.Zend 引擎执行opcode,返回执行结果在PHP cli模式下,每次执行PHP脚本,四个步骤都会依次执行一遍;在PHP-FPM模式下,步骤1)在PHP-FPM启动时执行一次,后续的请求中不再执行;步骤2)~4)每个请求都要执行一遍;其实步骤2)、3)生成的语法树和opcode,同一个PHP脚本每次运行的结果都是一样的,在PHP-FPM模式下,每次请求都要处理一遍,是对系统资源极大的浪费,那么有没有办法优化呢?当然有,如:OPCache:前身是Zend Optimizer+ ,是 Zend Server 的一个开源组件;官方出品,强力推荐APC:Alternative PHP Cache 是一个开放自由的 PHP opcode 缓存组件,用于缓存、优化 PHP 中间代码;已经不更新了不推荐APCu:是APC的一个分支,共享内存,缓存用户数据,不能缓存opcode,可以配合Opcache 使用eAccelerate:同样是不更新了,不推荐xCache:不再推荐使用了OPCache 介绍OPCache 是Zend官方出品的,开放自由的 opcode 缓存扩展,还具有代码优化功能,省去了每次加载和解析 PHP 脚本的开销。PHP 5.5.0 及后续版本中已经绑定了 OPcache 扩展。缓存两类内容:OPCodeInterned String,如注释、变量名等OPCache 原理OPCache缓存的机制主要是:将编译好的操作码放入共享内存,提供给其他进程访问。这里就涉及到内存共享机制,另外所有内存资源操作都有锁的问题,我们一一解读。3.1 共享内存UNIX/Linux 系统提供很多种进程间内存共享的方式:1.System-V shm API: System V共享内存,sysv shm是持久化的,除非被一个进程明确的删除,否则它始终存在于内存里,直到系统关机;2.mmap API:mmap映射的内存在不是持久化的,如果进程关闭,映射随即失效,除非事先已经映射到了一个文件上内存映射机制mmap是POSIX标准的系统调用,有匿名映射和文件映射两种mmap的一大优点是把文件映射到进程的地址空间避免了数据从用户缓冲区到内核page cache缓冲区的复制过程;当然还有一个优点就是不需要频繁的read/write系统调用3.POSIX API:System V 的共享内存是过时的, POSIX共享内存提供了使用更简单、设计更合理的API.4.Unix socket APIOPCache 使用了前三个共享内存机制,根据配置或者默认mmap 内存共享模式。依据PHP字节码缓存的场景,OPCache的内存管理设计非常简单,快速读写,不释放内存,过期数据置为Wasted。当Wasted内存大于设定值时,自动重启OPCache机制,清空并重新生成缓存。3.2 互斥锁任何内存资源的操作,都涉及到锁的机制。共享内存:一个单位时间内,只允许一个进程执行写操作,允许多个进程执行读操作;写操作同时,不阻止读操作,以至于很少有锁死的情况。这就引发另外一个问题:新代码、大流量场景,进程排队执行缓存opcode操作;重复写入,导致资源浪费。4. OPCache 缓存解读OPCache 是官方的Opcode 缓存解决方案,在PHP5.5版本之后,已经打包到PHP源码中一起发布。它将PHP编译产生的字节码以及数据缓存到共享内存中, 在每次请求,从缓存中直接读取编译后的opcode,进行执行。通过节省脚本的编译过程,提高PHP的运行效率。如果正在使用APC扩展,做同样的工作,现在强烈推荐OPCache来代替,尤其是PHP7中。4.1 OPCode 缓存Opcache 会缓存OPCode以及如下内容:PHP脚本涉及到的函数PHP脚本中定义的ClassPHP脚本文件路径PHP脚本OPArrayPHP脚本自身结构/内容4.2 Interned String 缓存首先我们需要理解,什么是 Interned String?在PHP5.4的时候, 引入了Interned String机制, 用于优化PHP对字符串的存储和处理。尤其是处理大块的字符串,比如PHP doces时,Interned String 可以优化内存。Interned String 缓存的内容包括:变量名称、类名、方法名、字符串、注释等。在PHP-FPM模式中,Interned String 缓存字符,仅限于Worker 进程内部。而缓存到OPCache中,那么Worker进程之间可以使用 Interned String 缓存的字符串,节省内存。我们需要注意一个事情,在PHP开发中,一般会有大段的注释,也会被缓存到OPCache中。可以通过php.ini的配置,关闭注释的缓存。但是,像Zend Framework等框架中,会引用注释,所以,是否关闭注释的缓存,需要区别对待。OPCache 更新策略是缓存,都存在过期,以及更新策略等。而OPCache的更新策略非常简单,到期数据置为Wasted,达到设定值,清空缓存,重建缓存。这里需要注意:在高流量的场景下,重建缓存是一件非常耗费资源的事儿。OPCache 在创建缓存时并不会阻止其他进程读取。这会导致大量进程反复新建缓存。所以,不要设置OPCache过期时间每次发布新代码时,都会出现反复新建缓存的情况。如何避免呢?不要在高峰期发布代码,这是任何情况下都要遵守的规则代码预热,比如使用脚本批量调PHP 访问URL,或者使用OPCache 暴露的API 如opcache_compile_file() 进行编译缓存OPCache 的配置6.1 内存配置opcache.preferred_memory_model="mmap" OPcache 首选的内存模块。如果留空,OPcache 会选择适用的模块, 通常情况下,自动选择就可以满足需求。可选值包括:mmap,shm, posix 以及 win32。opcache.memory_consumption=64 OPcache 的共享内存大小,以兆字节为单位,默认64Mopcache.interned_strings_buffer=4 用来存储临时字符串的内存大小,以兆字节为单位,默认4Mopcache.max_wasted_percentage=5 浪费内存的上限,以百分比计。如果达到此上限,那么 OPcache 将产生重新启动续发事件。默认56.2 允许缓存的文件数量以及大小opcache.max_accelerated_files=2000 OPcache 哈希表中可存储的脚本文件数量上限。真实的取值是在质数集合 { 223, 463, 983, 1979, 3907, 7963, 16229, 32531, 65407, 130987 } 中找到的第一个大于等于设置值的质数。设置值取值范围最小值是 200,最大值在 PHP 5.5.6 之前是 100000,PHP 5.5.6 及之后是 1000000。默认值2000opcache.max_file_size=0 以字节为单位的缓存的文件大小上限。设置为 0 表示缓存全部文件。默认值06.3 注释相关的缓存opcache.load_commentsboolean 如果禁用,则即使文件中包含注释,也不会加载这些注释内容。本选项可以和 opcache.save_comments 一起使用,以实现按需加载注释内容。opcache.fast_shutdown boolean 如果启用,则会使用快速停止续发事件。所谓快速停止续发事件是指依赖 Zend 引擎的内存管理模块 一次释放全部请求变量的内存,而不是依次释放每一个已分配的内存块。6.4 二级缓存的配置opcache.file_cache 配置二级缓存目录并启用二级缓存。启用二级缓存可以在 SHM 内存满了、服务器重启或者重置 SHM 的时候提高性能。默认值为空字符串 "",表示禁用基于文件的缓存。opcache.file_cache_onlyboolean 启用或禁用在共享内存中的 opcode 缓存。opcache.file_cache_consistency_checksboolean 当从文件缓存中加载脚本的时候,是否对文件的校验和进行验证。opcache.file_cache_fallbackboolean 在 Windows 平台上,当一个进程无法附加到共享内存的时候, 使用基于文件的缓存,也即:opcache.file_cache_only=1。需要显示的启用文件缓存。
-
【MySQL】如何优化无索引的join 现在有张 user 表,这个 user 表很简单,一个主键 id,也就是我们的用户 id,还有个 name 字段,很明显就是用户的姓名。这时候还有一张 user_info 表,这个 user_info 表存的是用户的一些其他信息,有 user_id 代表用户的 id,还有个 account 代表用户的存款。遍历循环查询如果要查出所有用户的姓名和存款,我们可以这样查: data = select * from user; for (i=0;i<len(data);i++) { info = select account from user_info where user_id= data[i].user_id }这种方式最直观,先通过 user 表拿到所有的用户信息,然后根据连接键 user_id 去 user_info 表里查询对应的 account,这样就能得到想要的数据,但是这种方式几个问题:第一次全表扫描 user 表需要一次网络通信,假设 user 表的数据量是n。然后循环查询 user_info 表,这里需要 n 次网络通信因此一共需要 n+1 次网络通信,如果使用的是长连接,还能省去 3 次握手的时间,如果是短连接,整体的开销会更大。其次如果 user_id 没有索引,那么整体更伤,假设 user_info 一共有 m 条数据,那么扫描的次数是怎么算的呢?首先 user 表是全表扫,一共需要查询 n 次。由于 user_info 表的 user_id 没有索引,那么每次查询等于都是全表扫,总共需要 n*m 次。因此这种查询的方式一共需要扫描 n+n*m 次。当然一般不会出现 user_id 没有索引的情况,在 user_id 有索引的时候,可以根据索引快速定位到我们的目标数据,并不需要全表扫描,因此总共需要扫描的行数为 n+m 次。join 查询一般对于这种情况的查询,我们会用 join 来做,于是我们的 sql 或许如下: select a.name,b.account from user a left join user_info b on a.id=b.user_id首先从网络通信上来说,总体只需要一次通信,至于 MySQL 内部怎么处理数据,怎么把我们想要的数据返回回来是它内部的事。其次我们来看看这种 join 方式的原理:从 user 表扫描一条数据,然后去 user_info 表中匹配在连接键 user_id 有索引的情况下,可以利用索引快速匹配然后把 user 表中的 name 和 user_info 表中的 account 作为结果集的一部分返回回去重复 1-3 步骤,直至 user 表扫描完毕,数据全部返回。其中第三步骤,每次组合一条数据的时候,并不是立马返回给客户端,这样效率太低,其实是有缓冲区的,也就是先把数据放在缓冲区中,等缓冲区满了,一次性响应给客户端可以大大提升效率。从原理来看和上面的遍历查询差不多,主要不同的是,客户端不需要和服务端多次通信。join buffer (Block Nested Loop)以上说的还是连接键有索引的,我们来看看连接键没有索引的情况,这时候你通过 explain 来看 MySQL 的执行计划,你会发现其中 user_info 的 extra 字段中会提示这个Using where; Using join buffer (Block Nested Loop)这是什么意思呢?因为没有索引,所以每次去 user 表得到一条数据的时候,肯定是要再到 user_info 表做全表扫描,这个扫描的成本我们上面也提到了,就是 n+n*m=n(1+m),因此这个时间复杂度是和 n 成正比的,这也是为什么我们一般推荐「小表驱动大表」的方式。但是如果我们按照这个方式来做 join,未免开销太大了,太耗时了,于是还是沿用老套路,也就是用个临时存储区,也就是 extra 中的 join buffer,有了这个 join buffer 后,首先会把 user 表的数据放进去,然后扫描 user_info 表,每扫描一行数据,就和 join buffer 中的每一行 user 数据匹配,如果匹配上了,也就是我们要的结果,因为 user_info 表有 m 条数据,因此需要判断 n*m 次,咦!这个也没减少呀,还是和上面的一样。其实不一样,这里的 m 条数据其实每次都是和内存中的 n 条数据做匹配的,并非磁盘,内存的速度不用多说。聪明的读者可能会发现,如果 user 表的数据很多,join buffer 能放得下吗? +------------------+--------+ | Variable_name | Value | +------------------+--------+ | join_buffer_size | 262144 | +------------------+--------+buffer 默认是 256K,多的话确实放不下,放不下的话,怎么办?其实也很简单,分段放即可,当读 user 表的数据占满 buffer 的时候,就不放了,然后直接和 user_info 做匹配,逻辑还是同上,在 buffer 的数据处理完之后,就清空它,接着上次的位置继续读入数据,再次重复同样的逻辑,直至数据读完。虽说连接键没有索引的时候,会通过 join buffer 来优化速度,但是现实中,还是建议大家尽量要保证连接键有索引。
-
-
-
【MySQL】查看mysql版本的四种方法 **1:在终端下:mysql -V。 以下是代码片段:** [shengting@login ~]$ mysql -V mysql Ver 14.7 Distrib 4.1.10a, for redhat-linux-gnu (i686) **2:在mysql中:mysql> status;** 以下是代码片段: mysql> status; -------------- mysql Ver 14.7 Distrib 4.1.10a, for redhat-linux-gnu (i686) Connection id: 416 SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 3.23.56-log Protocol version: 10 Connection: Localhost via UNIX socket Client characterset: latin1 Server characterset: latin1 UNIX socket: /tmp/mysql_3311.sock Uptime: 62 days 21 hours 21 min 57 sec Threads: 1 Questions: 584402560 Slow queries: 424 Opens: 59664208 Flush tables: 1 Open tables: 64 Queries per second avg: 107.551 **3:在help里面查找** 以下是代码片段: [shengting@login ~]$ mysql --help | grep Distrib mysql Ver 14.7 Distrib 4.1.10a, for redhat-linux-gnu (i686) **4:使用mysql的函数** 以下是代码片段: mysql> select version(); +-------------+ | version() | +-------------+ | 3.23.56-log | +-------------+ 1 row in set (0.00 sec)
-
-
【Laravel】laravel使用总结 laravel框架最大的特点和优秀之处就是集合了php比较新的特点,以及各种各样的设计模式,Ioc模式,依赖注入等一、Laravel有哪些特点1 强大的rest router:用简单的回调函数就可以调用,快速绑定controller和router2 artisan:命令行工具,很多手动的工作都自动化3 可继承的模板,简化view的开发和管理4 blade模板:渲染速度更快5 ORM操作数据库6 migration:管理数据库和版本控制7 测试功能也很强大8 composer也是亮点9 laravel框架引入了门面,依赖注入,Ioc模式,以及各种各样的设计模式等二、架构模式laravel框架是使用了服务组件化的开发模式,由多个服务提供者构成了组件,再由多个组件提供不同的服务,然后是多个服务构成了项目服务提供者是应用配置的核心,是通过 register方法中绑定服务到服务容器的。三、涉及到的设计模式laravel框架使用了大量设计模式,使模块之间耦合度很低,服务容器可以方便的扩展框架功能以及编写测试。1.ORM - 对象关系映射模式2 依赖注入与IOC容器 - 策略模式3 监听与触发 - 观察者模式4 门面模式 - 静态代理还有其他的,比如注册服务的时候用到单例模式等。四、服务方面能快速开发出功能,自带各种方便的服务,比如数据验证、队列、缓存、数据迁移、测试、artisan 命令行等等,还有强大的 ORM,artisan强大的命令行工具,实现自动化。Laravel安全功能有效地利用了盐散列和加密码机制,Bcrypt哈希算法”来创建加密密码。五、框架的其他知识点服务容器:是一个用于管理类依赖和执行依赖注入的强大工具。其实质是通过构造函数或者某些情况下通过「setter」方法将类依赖注入到类中。 门面:为应用服务容器中的绑定类提供了一个「静态」接口 ,优点:在维护时能够提供更加易于测试、更加灵活、简明优雅的语法。契约:用来规划服务提供者的格式、方法、参数等,给服务提供者规范了一定约束。反射:主要用来动态地获取系统中类、实例对象、方法等语言构件的信息,通过发射API函数可以实现对这些语言构件信息的动态获取和动态操作等。后期静态绑定:用于在继承范围内引用静态调用的类,即在类的继承过程中,使用的类不再是当前类,而是调用的类。六、生命周期生命周期如下:入口文件-请求web服务器导入这个文件-载入 Composer 生成的自动加载启动核心文件-内核启动(服务提供者启动框架的各种组件)-交给路由分发到到(控制器,中间件等)-逻辑处理-返回结果七、laravel框架运用到的repository模式的主要思想建立一个数据操作代理层,把controller里的数据操作剥离出来,这样做有几个好处:1 把数据处理逻辑分离使得代码更容易维护2 数据处理逻辑和业务逻辑分离,可以对这两个代码分别进行测试3 减少代码重复4 降低代码出错的几率5 让controller代码的可读性大大提高
-
-
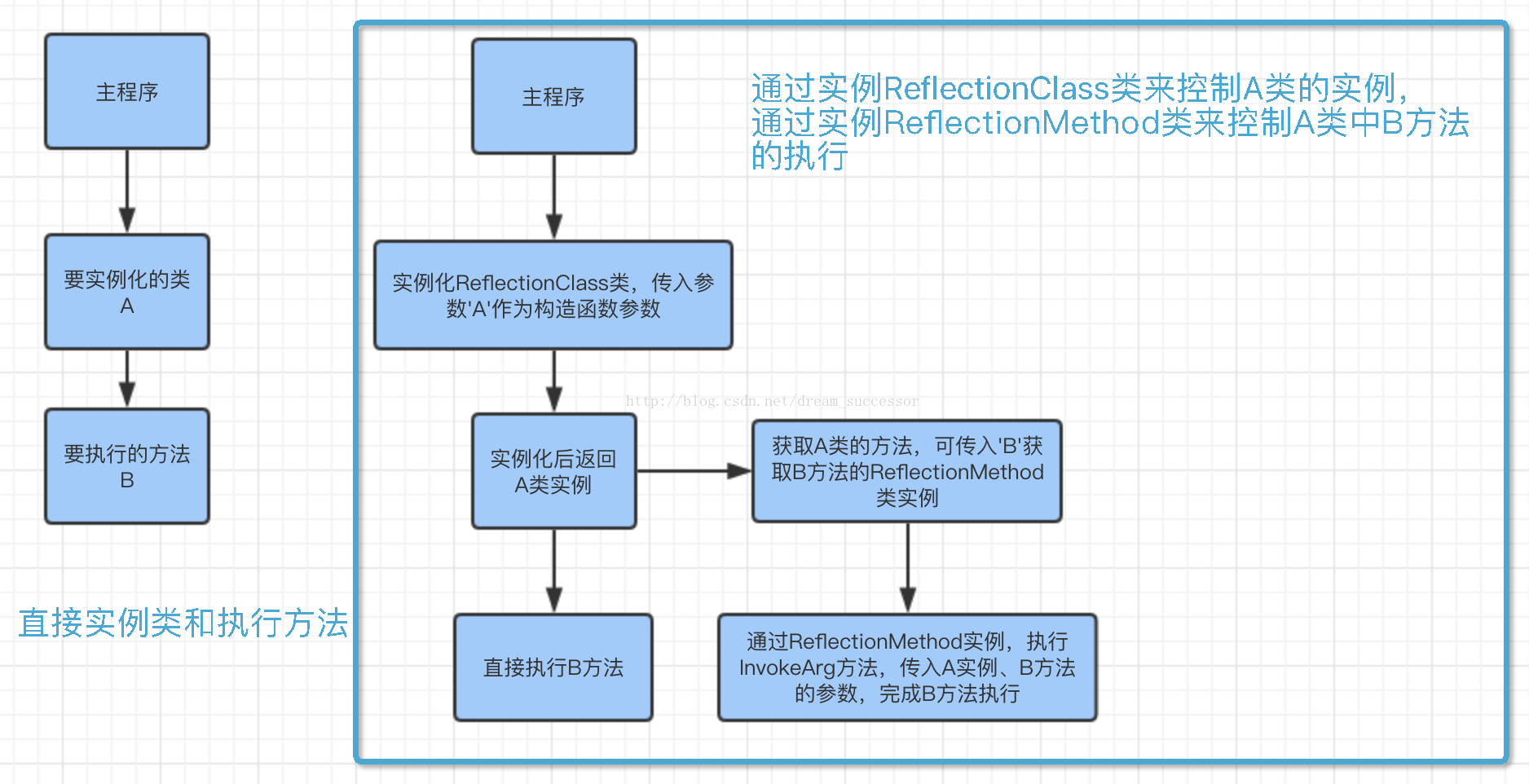
【PHP】PHP反射 一、前言Reflection(反射)是Java程序开发语言的特征之一,它允许运行中的Java程序对自身进行检查,或者说“自审”,并能直接操作程序的内部属性。这一特征在实际应用中也许用得不是很多。PHP从5.0开始完美支持反射API。PHP反射可以用于观察并修改程序在运行时的行为。一个面向反射的(reflection-oriented)程序组件可以监测一个范围内的代码执行情况,可以根据期望的目标与此相关的范围修改本身。PHP5具有完整的反射API,添加了对类、接口、函数、方法和扩展进行反向工程的能力。二、概念反射是指在PHP运行状态中,扩展分析PHP程序,导出或提出关于类、方法、属性、参数等的详细信息,包括注释。这种动态获取信息以及动态调用对象方法的功能称为反射API。三、PHP反射的基本语法实现反射的方法有很多,可以通过实例化一个专门控制类的ReflectionClass类来实现反射,也可以在已有类实例的情况下,通过直接实例化ReflectionMethod类来执行反射方法,原理如图:以下是对反射类和反射方法类的基本用法:1、反射类(1) $reflectClass = new ReflectionClass(<类名>); 传入类名字符串,返回控制目标类的ReflectionClass类实例; (2) $reflectClass->getConstant(<常量名>); 传入类中定义了的常量名,返回常量值,可通过$reflectClass->getConstants返回类中所有定义的常量的数组; (3) $class = $reflectClass->newInstance(); 实例化类,返回目标类实例;也可通过$reflectClass->newInstanceArgs(<参数数组>)传入实例化的构造函数参数进行实例化; 2、反射方法(1) $reflectMethod = new ReflectionMethod(<方法名>); 传入方法名名字符串,返回控制目标方法的ReflectionMethod类实例; (2) $parameters = $reflectMethod->getParameters(); 获取该类所需的参数名,该方法返回一个包含所有参数名的二维数组; (3) $name = $parameters->getName(); 返回要执行的方法所需参数数组的单个参数名,可通过foreach循环逐一获取和赋值; (4) $reflectMethod->invokeArgs(<类实例>,<执行该方法所需参数数组>); 传入类实例和方法参数,执行方法,返回执行结果。 3、反射类和反射方法中其他常用的用法:ReflectionClass: ReflectionMethod: 4、除了ReflectionClass和ReflectionMethod,我们对于类中的参数、属性和php服务的环境变量、扩展等参数也是可以通过反射API的一些方法来执行的,如下:四、反射在实际应用中的使用1、反射可以用于文档、文件生成。可以用它对文件里的类进行扫描,逐个生成描述文档;2、既然反射可以探知类的内部结构,那么可以用它做hook实现插件功能;3、可以用于做动态代理,在未知或者不确定类名的情况下,动态生成和实例化一些类和执行方法;4、对于多次继承的类,我们可以通过多次反射探索到基类的结构,或者采用递归的形式反射,实现实例化所有继承类,这即是PHP依赖注入的原理。五、PHP反射的优缺点优点1、支持反射的语言提供了一些在低级语言中难以实现的运行时特性。2、可以在一定程度上避免硬编码,提供灵活性和通用性。3、可以作为一个第一类对象发现并修改源代码的结构(如代码块、类、方法、协议等)。4、可以在运行时像对待源代码语句一样计算符号语法的字符串(类似JavaScript的eval()函数),进而可将跟class或function匹配的字符串转换成class或function的调用或引用。5、可以创建一个新的语言字节码解释器来给编程结构一个新的意义或用途。缺点1、此技术的学习成本高。面向反射的编程需要较多的高级知识,包括框架、关系映射和对象交互,以利用更通用的代码执行。2、同样因为反射的概念和语法都比较抽象,过多地滥用反射技术会使得代码难以被其他人读懂,不利于合作与交流。3、由于将部分信息检查工作从编译期推迟到了运行期,此举在提高了代码灵活性的同时,牺牲了一点点运行效率。4、通过深入学习反射的特性和技巧,它的劣势可以尽量避免,但这需要许多时间和经验的积累。如何使用反射API? class person{ public $name; public $gender; public function say(){ echo $this->name," \tis ",$this->gender,"\r\n"; } public function set($name, $value) { echo "Setting $name to $value \r\n"; $this->$name= $value; } public function get($name) { if(!isset($this->$name)){ echo '未设置'; $this->$name="正在为你设置默认值"; } return $this->$name; } } $student=new person(); $student->name='Tom'; $student->gender='male'; $student->age=24; 现在,要获取这个student对象的方法和属性列表该怎么做呢?如以下代码所示: // 获取对象属性列表 $reflect = new ReflectionObject($student); $props = $reflect->getProperties(); foreach ($props as $prop) { print $prop->getName() ."\n"; } // 获取对象方法列表 $m=$reflect->getMethods(); foreach ($m as $prop) { print $prop->getName() ."\n"; } 也可以不用反射API,使用class函数,返回对象属性的关联数组以及更多的信息: // 返回对象属性的关联数组 var_dump(get_object_vars($student)); // 类属性 var_dump(get_class_vars(get_class($student))); // 返回由类的方法名组成的数组 var_dump(get_class_methods(get_class($student))); 假如这个对象是从其他页面传过来的,怎么知道它属于哪个类呢?一句代码就可以搞定: // 获取对象属性列表所属的类 echo get_class($student); 反射API的功能显然更强大,甚至能还原这个类的原型,包括方法的访问权限等,如: // 反射获取类的原型 $obj = new ReflectionClass('person'); $className = $obj->getName(); $Methods = $Properties = array(); foreach($obj->getProperties() as $v) { $Properties[$v->getName()] = $v; } foreach($obj->getMethods() as $v){ $Methods[$v->getName()] = $v; } echo "class {$className}\n{\n"; is_array($Properties)&&ksort($Properties); foreach($Properties as $k => $v) { echo "\t"; echo $v->isPublic() ? ' public' : '',$v->isPrivate() ? ' private' : '', $v->isProtected() ? ' protected' : '', $v->isStatic() ? ' static' : ''; echo "\t{$k}\n"; } echo "\n"; if(is_array($Methods)) ksort($Methods); foreach($Methods as $k => $v) { echo "\tfunction {$k}(){}\n"; } echo "}\n"; 输出如下: class person { public gender public name function get(){} function set(){} function say(){} } 不仅如此,PHP手册中关于反射API更是有几十个,可以说,反射完整地描述了一个类或者对象的原型。反射不仅可以用于类和对象,还可以用于函数、扩展模块、异常等。 反射的作用? ------ 反射可以用于文档生成。因此可以用它对文件里的类进行扫描,逐个生成描述文档。 既然反射可以探知类的内部结构,那么是不是可以用它做hook实现插件功能呢?或者是做动态代理呢? 例如: class mysql { function connect($db) { echo "连接到数据库${db[0]}\r\n"; } } class sqlproxy { private $target; function construct($tar) { $this->target[] = new $tar(); } function call($name, $args) { foreach ($this->target as $obj) { $r = new ReflectionClass($obj); if ($method = $r->getMethod($name)) { if ($method->isPublic() && !$method->isAbstract()) { echo "方法前拦截记录LOG\r\n"; $method->invoke($obj, $args); echo "方法后拦截\r\n"; } } } } } $obj = new sqlproxy('mysql'); $obj->connect('member'); 在平常开发中,用到反射的地方不多:一个是对对象进行调试,另一个是获取类的信息。在MVC和插件开发中,使用反射很常见,但是反射的消耗也很大,在可以找到替代方案的情况下,就不要滥用。 很多时候,善用反射能保持代码的优雅和简洁,但反射也会破坏类的封装性,因为反射可以使本不应该暴露的方法或属性被强制暴露了出来,这既是优点也是缺点。 <p>原文链接:https://blog.csdn.net/dream_successor/article/details/78287016</p>
-
【PHP】thinkphp5.1清除缓存 包括缓存日志 编译文件 /** * 清除缓存 */ public function clearCache(){ \think\facade\Cache::clear(); return ZHTReturn('清除成功',1); } /** * 清除模版缓存但不删除temp目录 */ public function clearTemp() { $path = env('RUNTIME_PATH'); // $path = env(); // dump($path); // die; array_map('unlink',glob($path.'temp\*.php')); return ZHTReturn('清除成功',1); } /** * 清除日志缓存并删出log空目录 */ public function clearLog() { $path = env('RUNTIME_PATH'); $path_log = glob($path.'log\*'); foreach ($path_log as $val) { array_map('unlink', glob($val . '\*.log')); rmdir($val); } return ZHTReturn('清除成功',1); } /** * 清除所有缓存 */ public function clearAll() { \think\facade\Cache::clear(); $path = env('RUNTIME_PATH'); array_map('unlink',glob($path.'temp\*.php')); $path_log = glob($path.'log\*'); foreach ($path_log as $val) { array_map('unlink', glob($val . '\*.log')); rmdir($val); } return ZHTReturn('清除成功',1); }
-
【PHP】获取字符串的两个字符中间的内容 /** * Author: 小破孩 * Email: 3584685883@qq.com * Time: 2022/2/14 16:12 * @param $str * @param $separator * @param string $mark * @return bool|false|mixed|string * Description:获取字符串 */ public function getSubStr($str,$separator,$mark=':'){ $arr = explode($separator,$str); if (empty($arr) || !isset($arr[1])) { return false; } $str = $arr[1]; if (strpos($str,$mark) !== false) { return substr($str,0,strpos($str,$mark)); }else{ return $str; } }
-
【Git】pull遇到错误:error: Your local changes to the following files would be overwritten by merge:本地有修改时,如何合并远程更新?(保留/不保留本地修改两种方案) 本地有修改时,如何合并远程更新?(保留/不保留本地修改两种方案)在日常开发中,经常会遇到这样的场景:本地代码做了修改,但还没提交,此时远程仓库已有其他人推送的更新。直接执行 git pull 可能会报错(因本地修改与远程更新冲突),该如何处理?一、想要保留本地修改(推荐)通过「暂存本地修改→拉取远程更新→恢复本地修改」三步操作,既能同步远程最新代码,又能保留本地未提交的改动。具体步骤:暂存本地修改 用 git stash 将本地所有未提交的修改(包括工作区和暂存区)暂存到「Git 栈」中,此时工作区会恢复到上次提交的干净状态:git stash✅ 效果:本地修改被临时存储,工作区与远程仓库当前状态一致,为后续拉取远程代码扫清障碍。拉取远程更新 此时可以安全地拉取远程仓库的最新代码(以 origin 远程的 master 分支为例):git pull origin master✅ 效果:远程最新代码被合并到本地当前分支,本地代码与远程同步。恢复本地修改并处理冲突 用 git stash pop 将之前暂存的本地修改恢复到工作区:git stash pop⚠️ 注意:如果本地修改与远程更新存在冲突(同一文件同一位置有不同修改),Git 会提示 Auto-merging <文件名> 并标记冲突位置,此时需要手动处理:打开冲突文件,找到类似以下标记的内容:<<<<<<< Updated upstream # 远程更新的内容 ... ======= # 分隔线 ... >>>>>>> Stashed changes # 本地暂存的修改编辑文件,保留需要的内容(删除冲突标记 <<<<<<<、=======、>>>>>>>);处理完冲突后,执行 git add <冲突文件> 标记为已解决,再正常提交即可。补充:stash 相关实用命令查看暂存列表(若多次 stash,可区分不同暂存):git stash list # 输出格式:stash@{0}: WIP on <分支名>: <提交信息>恢复指定暂存(如恢复第 1 条暂存,索引从 0 开始):git stash apply stash@{0} # apply 保留暂存记录,pop 会删除暂存记录删除暂存记录(若无需恢复):git stash drop stash@{0} # 删除指定暂存 git stash clear # 清空所有暂存二、不想要保留本地修改(谨慎使用)若本地修改无价值,可直接丢弃本地所有未提交的改动,用远程代码覆盖本地。具体步骤:强制恢复本地到最近一次提交状态 用 git reset --hard 丢弃本地所有未提交的修改(包括工作区和暂存区),注意:此操作不可恢复,需确保本地修改确实无用:git reset --hard拉取远程更新覆盖本地 拉取远程最新代码,此时因本地已无修改,可直接覆盖:git pull origin master三、总结与最佳实践保留本地修改:优先用 git stash → git pull → git stash pop,安全且能处理冲突,适合大多数开发场景。不保留本地修改:仅在确认本地修改无价值时使用 git reset --hard → git pull,务必谨慎(避免误删重要代码)。协作建议:日常开发中,建议频繁提交本地修改(小步提交),减少 stash 使用;拉取远程代码前,先确认本地修改是否已保存,避免冲突。
-
【Git】Git 服务器怎么避免反复密码输入 Git 记住密码:一键配置永久保存凭证(附安全说明)在使用 Git 操作远程仓库(如 GitHub、GitLab 等)时,每次执行 git pull、git push 都需要输入用户名和密码,非常繁琐。通过配置 Git 凭证助手,可以实现一次输入、永久保存,彻底解决重复输入的问题。一、核心命令:配置凭证存储# 全局配置 Git 使用 "store" 凭证助手(保存密码到本地文件) git config --global credential.helper store命令作用:credential.helper store 是 Git 的一种凭证存储方式,会将用户名和密码以明文形式保存在本地文件中;--global 表示对当前用户的所有 Git 仓库生效(局部配置可去掉 --global,仅对当前仓库有效)。二、使用步骤(只需一次)执行配置命令 在 Git Bash 中输入上述命令,配置凭证存储方式:git config --global credential.helper store执行一次需要认证的 Git 操作 比如拉取(git pull)或推送(git push)远程仓库,此时会提示输入用户名和密码:git pull origin main # 示例:拉取远程 main 分支按照提示输入正确的用户名和密码后,操作会正常执行。后续操作无需再输入密码 完成上述步骤后,Git 会自动保存凭证,下次执行 git pull、git push 等操作时,会直接使用保存的用户名和密码,无需手动输入。三、凭证保存位置(明文存储)配置后,用户名和密码会保存在以下文件中(可手动查看或编辑):Windows 系统:C:\Users\你的用户名\.git-credentialsLinux/Mac 系统:~/.git-credentials(~ 表示用户主目录,如 /home/你的用户名/)文件内容格式类似:https://用户名:密码@远程仓库域名 # 示例:https://xiaohong:123456@github.com四、安全性说明(重要!)明文存储风险:store 方式会将密码以明文形式保存在本地文件中,若电脑被他人访问,可能导致密码泄露。不建议在公共电脑、共享设备上使用。适用场景:个人专用电脑,且对凭证安全性要求不高的场景(如私人仓库、内部测试仓库)。五、如何清除已保存的凭证?如果需要更换密码或删除保存的凭证,直接删除上述 .git-credentials 文件即可:Windows:找到 C:\Users\你的用户名\.git-credentials 并删除;Linux/Mac:执行命令 rm ~/.git-credentials。删除后,下次执行 Git 操作时会重新提示输入用户名和密码。六、更安全的替代方案(推荐)如果担心明文存储的安全问题,建议使用加密存储的凭证助手,不同系统有默认推荐:Windows:使用 git config --global credential.helper manager-core(依赖 Git Credential Manager,自动加密存储到系统凭据管理器);Mac:使用 git config --global credential.helper osxkeychain(密码会加密存储到系统钥匙串);Linux:使用 git config --global credential.helper libsecret(依赖 libsecret 库,加密存储到系统密钥环)。这些方式会对凭证进行加密存储,安全性远高于 store 方式,推荐在正式环境中使用。总结git config --global credential.helper store 是一种简单高效的 Git 凭证保存方案,适合个人专用设备快速解决重复输入密码的问题,但需注意其明文存储的安全性。若对安全要求较高,建议使用系统自带的加密凭证助手。
-
【PHP】PHP提取多维数组指定列的方法 $arr = array( '0' => array('id' => 1, 'name' => 'name1'), '1' => array('id' => 2, 'name' => 'name2'), '2' => array('id' => 3, 'name' => 'name3'), '3' => array('id' => 4, 'name' => 'name4'), '4' => array('id' => 5, 'name' => 'name5'), ); //需要得到的结果:$name_list = array('name1', 'name2', 'name3', 'name4', 'name5'); 1、使用array_column() PHP在5.5.0版本之后,添加了一个专用的函数array_column() 方法: $name_list = array_column($arr, 'name'); 2、array_walk()方法 array_walk()使用用户自定义函数对数组中的每个元素做回调处理 $name_list = array(); array_walk($arr, function($value, $key) use (&$name_list ){ $name_list [] = $value['name']; }); 3、array_map()方法 array_map()函数和array_walk() 作用类似,将回调函数作用到给定数组的单元上 $name_list = array(); array_map(function($value) use (&$name_list){ $name_list[] = $value['name']; }, $arr); 4、foreach循环遍历方法 foreach()循环相对上面的方法效率稍微低一些 $name_list = array(); foreach ($arr as $value) { $name_list[] = $value['name']; } 5、array_map变种 把$arr数组的每一项值的开头值移出,并获取移除的值作为新数组。注意此时新数组$name_list的键仍是原数组$arr的键 $name_list = array_map('array_shift', $arr); //注意:该功能会获取$arr中的 id 列,而不是name 列。 //另外,如果需要获取二维数组每一项的开头列或结尾列,也可以这样做: $name_list = array_map('reset', $arr); $name_list = array_map('end', $arr); //这三个变种方法作用比较局限,仅在获取第一列或最后一列的时候有用,在 //复杂的数组中就难以发挥作用了。
-
【MySQL】一个表的数据导入到另一个表 1.如果2张表的字段一致,并且希望插入全部数据,可以用这种方法: INSERT INTO 目标表 SELECT * FROM 来源表; insert into insertTest select * from insertTest2; 2.如果只希望导入指定字段,可以用这种方法: INSERT INTO 目标表 (`字段1`, `字段2`, ...) SELECT `字段1`, `字段2`, ... FROM 来源表;(这里的话字段必须保持一致) insert into insertTest2(`id`) select `id` from insertTest2; 3.如果您需要只导入目标表中不存在的记录,可以使用这种方法: INSERT INTO 目标表 (`字段1`, `字段2`, ...) SELECT `字段1`, `字段2`, ... FROM 来源表 WHERE not exists (select * from 目标表 where 目标表.比较字段 = 来源表.比较字段); 1>.插入多条记录: insert into insertTest2 (`id`,`name`) select `id`,`name` from insertTest where not exists (select * from insertTest2 where insertTest2.`id`=insertTest.id); 2>.插入一条记录: insert into insertTest (`id`, `name`) SELECT 100, 'liudehua' FROM dual WHERE not exists (select * from insertTest where insertTest.`id` = 100);
-
【MySQL】使用MySQL,请用好 JSON 这张牌! 关系型的结构化存储存在一定的弊端,因为它需要预先定义好所有的列以及列对应的类型。但是业务在发展过程中,或许需要扩展单个列的描述功能,这时,如果能用好 JSON 数据类型,那就能打通关系型和非关系型数据的存储之间的界限,为业务提供更好的架构选择。 当然,很多同学在用 JSON 数据类型时会遇到各种各样的问题,其中最容易犯的误区就是将类型 JSON 简单理解成字符串类型。但当你看完这篇文章后,会真正认识到 JSON 数据类型的威力,从而在实际工作中更好地存储非结构化的数据。 ## JSON 数据类型 ## JSON(JavaScript Object Notation)主要用于互联网应用服务之间的数据交换。MySQL 支持RFC 7159定义的 JSON 规范,主要有 JSON 对象 和 JSON 数组 两种类型。下面就是 JSON 对象,主要用来存储图片的相关信息: { "Image": { "Width": 800, "Height": 600, "Title": "View from 15th Floor", "Thumbnail": { "Url": "http://www.example.com/image/xx9943", "Height": 125, "Width": 100 }, "IDs": [116, 943, 234, 38793] } } 从中你可以看到, JSON 类型可以很好地描述数据的相关内容,比如这张图片的宽度、高度、标题等(这里使用到的类型有整型、字符串类型)。 JSON对象除了支持字符串、整型、日期类型,JSON 内嵌的字段也支持数组类型,如上代码中的 IDs 字段。 另一种 JSON 数据类型是数组类型,如: [ { "precision": "zip", "Latitude": 37.7668, "Longitude": -122.3959, "Address": "", "City": "SAN FRANCISCO", "State": "CA", "Zip": "94107", "Country": "US" }, { "precision": "zip", "Latitude": 37.371991, "Longitude": -122.026020, "Address": "", "City": "SUNNYVALE", "State": "CA", "Zip": "94085", "Country": "US" } ] 上面的示例演示的是一个 JSON 数组,其中有 2 个 JSON 对象。 到目前为止,可能很多同学会把 JSON 当作一个很大的字段串类型,从表面上来看,没有错。但本质上,JSON 是一种新的类型,有自己的存储格式,还能在每个对应的字段上创建索引,做特定的优化,这是传统字段串无法实现的。JSON 类型的另一个好处是无须预定义字段,字段可以无限扩展。而传统关系型数据库的列都需预先定义,想要扩展需要执行 ALTER TABLE … ADD COLUMN … 这样比较重的操作。 需要注意是,JSON 类型是从 MySQL 5.7 版本开始支持的功能,而 8.0 版本解决了更新 JSON 的日志性能瓶颈。如果要在生产环境中使用 JSON 数据类型,强烈推荐使用 MySQL 8.0 版本。 讲到这儿,你已经对 JSON 类型的基本概念有所了解了,接下来,我们进入实战环节:如何在业务中用好JSON类型? ## 业务表结构设计实战 ## 用户登录设计 在数据库中,JSON 类型比较适合存储一些修改较少、相对静态的数据,比如用户登录信息的存储如下: DROP TABLE IF EXISTS UserLogin; CREATE TABLE UserLogin ( userId BIGINT NOT NULL, loginInfo JSON, PRIMARY KEY(userId) ); 由于当前业务的登录方式越来越多样化,如同一账户支持手机、微信、QQ 账号登录,所以这里可以用 JSON 类型存储登录的信息。 接着,插入下面的数据: SET @a = ' { "cellphone" : "1", "wxchat" : "码农", "77" : "1" } '; INSERT INTO UserLogin VALUES (1,@a); SET @b = ' { "cellphone" : "1188" } '; INSERT INTO UserLogin VALUES (2,@b); 从上面的例子中可以看到,用户 1 登录有三种方式:手机验证码登录、微信登录、QQ 登录,而用户 2 只有手机验证码登录。 而如果不采用 JSON 数据类型,就要用下面的方式建表: SELECT userId, JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.cellphone")) cellphone, JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.wxchat")) wxchat FROM UserLogin; +--------+-------------+--------------+ | userId | cellphone | wxchat | +--------+-------------+--------------+ | 1 | 11| 码农 | | 2 | 11| NULL | +--------+-------------+--------------+ 2 rows in set (0.01 sec) 当然了,每次写 JSON_EXTRACT、JSON_UNQUOTE 非常麻烦,MySQL 还提供了 ->> 表达式,和上述 SQL 效果完全一样: SELECT userId, loginInfo->>"$.cellphone" cellphone, loginInfo->>"$.wxchat" wxchat FROM UserLogin; 当 JSON 数据量非常大,用户希望对 JSON 数据进行有效检索时,可以利用 MySQL 的 函数索引 功能对 JSON 中的某个字段进行索引。 比如在上面的用户登录示例中,假设用户必须绑定唯一手机号,且希望未来能用手机号码进行用户检索时,可以创建下面的索引: ALTER TABLE UserLogin ADD COLUMN cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"); ALTER TABLE UserLogin ADD UNIQUE INDEX idx_cellphone(cellphone); 上述 SQL 首先创建了一个虚拟列 cellphone,这个列是由函数 loginInfo->>"$.cellphone" 计算得到的。然后在这个虚拟列上创建一个唯一索引 idx_cellphone。这时再通过虚拟列 cellphone 进行查询,就可以看到优化器会使用到新创建的 idx_cellphone 索引: EXPLAIN SELECT * FROM UserLogin WHERE cellphone = '11'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: UserLogin partitions: NULL type: const possible_keys: idx_cellphone key: idx_cellphone key_len: 1023 ref: const rows: 1 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.00 sec) 当然,我们可以在一开始创建表的时候,就完成虚拟列及函数索引的创建。如下表创建的列 cellphone 对应的就是 JSON 中的内容,是个虚拟列;uk_idx_cellphone 就是在虚拟列 cellphone 上所创建的索引。 CREATE TABLE UserLogin ( userId BIGINT, loginInfo JSON, cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"), PRIMARY KEY(userId), UNIQUE KEY uk_idx_cellphone(cellphone) ); 用户画像设计 某些业务需要做用户画像(也就是对用户打标签),然后根据用户的标签,通过数据挖掘技术,进行相应的产品推荐。比如: 在电商行业中,根据用户的穿搭喜好,推荐相应的商品; 在音乐行业中,根据用户喜欢的音乐风格和常听的歌手,推荐相应的歌曲; 在金融行业,根据用户的风险喜好和投资经验,推荐相应的理财产品。 在这,我强烈推荐你用 JSON 类型在数据库中存储用户画像信息,并结合 JSON 数组类型和多值索引的特点进行高效查询。假设有张画像定义表: CREATE TABLE Tags ( tagId bigint auto_increment, tagName varchar(255) NOT NULL, primary key(tagId) ); SELECT * FROM Tags; +-------+--------------+ | tagId | tagName | +-------+--------------+ | 1 | 70后 | | 2 | 80后 | | 3 | 90后 | | 4 | 00后 | | 5 | 爱运动 | | 6 | 高学历 | | 7 | 小资 | | 8 | 有房 | | 9 | 有车 | | 10 | 常看电影 | | 11 | 爱网购 | | 12 | 爱外卖 | +-------+--------------+ 可以看到,表 Tags 是一张画像定义表,用于描述当前定义有多少个标签,接着给每个用户打标签,比如用户 David,他的标签是 80 后、高学历、小资、有房、常看电影;用户 Tom,90 后、常看电影、爱外卖。 若不用 JSON 数据类型进行标签存储,通常会将用户标签通过字符串,加上分割符的方式,在一个字段中存取用户所有的标签: +-------+---------------------------------------+ |用户 |标签 | +-------+---------------------------------------+ |David |80后 ; 高学历 ; 小资 ; 有房 ;常看电影 | |Tom |90后 ;常看电影 ; 爱外卖 | +-------+--------------------------------------- 这样做的缺点是:不好搜索特定画像的用户,另外分隔符也是一种自我约定,在数据库中其实可以任意存储其他数据,最终产生脏数据。 用 JSON 数据类型就能很好解决这个问题: DROP TABLE IF EXISTS UserTag; CREATE TABLE UserTag ( userId bigint NOT NULL, userTags JSON, PRIMARY KEY (userId) ); INSERT INTO UserTag VALUES (1,'[2,6,8,10]'); INSERT INTO UserTag VALUES (2,'[3,10,12]'); 其中,userTags 存储的标签就是表 Tags 已定义的那些标签值,只是使用 JSON 数组类型进行存储。 MySQL 8.0.17 版本开始支持 Multi-Valued Indexes,用于在 JSON 数组上创建索引,并通过函数 member of、json_contains、json_overlaps 来快速检索索引数据。所以你可以在表 UserTag 上创建 Multi-Valued Indexes: ALTER TABLE UserTag ADD INDEX idx_user_tags ((cast((userTags->"$") as unsigned array))); 如果想要查询用户画像为常看电影的用户,可以使用函数 MEMBER OF: EXPLAIN SELECT * FROM UserTag WHERE 10 MEMBER OF(userTags->"$")\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: UserTag partitions: NULL type: ref possible_keys: idx_user_tags key: idx_user_tags key_len: 9 ref: const rows: 1 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) SELECT * FROM UserTag WHERE 10 MEMBER OF(userTags->"$"); +--------+---------------+ | userId | userTags | +--------+---------------+ | 1 | [2, 6, 8, 10] | | 2 | [3, 10, 12] | +--------+---------------+ 2 rows in set (0.00 sec) 如果想要查询画像为 80 后,且常看电影的用户,可以使用函数 JSON_CONTAINS: EXPLAIN SELECT * FROM UserTag WHERE JSON_CONTAINS(userTags->"$", '[2,10]')\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: UserTag partitions: NULL type: range possible_keys: idx_user_tags key: idx_user_tags key_len: 9 ref: NULL rows: 3 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) SELECT * FROM UserTag WHERE JSON_CONTAINS(userTags->"$", '[2,10]'); +--------+---------------+ | userId | userTags | +--------+---------------+ | 1 | [2, 6, 8, 10] | +--------+---------------+ 1 row in set (0.00 sec) 如果想要查询画像为 80 后、90 后,且常看电影的用户,则可以使用函数 JSON_OVERLAP: EXPLAIN SELECT * FROM UserTag WHERE JSON_OVERLAPS(userTags->"$", '[2,3,10]')\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: UserTag partitions: NULL type: range possible_keys: idx_user_tags key: idx_user_tags key_len: 9 ref: NULL rows: 4 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) SELECT * FROM UserTag WHERE JSON_OVERLAPS(userTags->"$", '[2,3,10]'); +--------+---------------+ | userId | userTags | +--------+---------------+ | 1 | [2, 6, 8, 10] | | 2 | [3, 10, 12] | +--------+---------------+ 2 rows in set (0.01 sec) JSON 类型是 MySQL 5.7 版本新增的数据类型,用好 JSON 数据类型可以有效解决很多业务中实际问题。最后,我总结下今天的重点内容: 使用 JSON 数据类型,推荐用 MySQL 8.0.17 以上的版本,性能更好,同时也支持 Multi-Valued Indexes; JSON 数据类型的好处是无须预先定义列,数据本身就具有很好的描述性; 不要将有明显关系型的数据用 JSON 存储,如用户余额、用户姓名、用户身份证等,这些都是每个用户必须包含的数据; JSON 数据类型推荐使用在不经常更新的静态数据存储。 原文链接:https://blog.csdn.net/java_pfx/article/details/116594654